6 Code Generation | 代码生成¶
约 2174 个字 3 行代码 25 张图片 预计阅读时间 7 分钟
朋辈辅学录播:编译原理速成(7) 代码生成
6.1 中间代码生成¶
AST 是 Intermediate Representation (IR) 的一种,但是要生成代码的时候需要先把它线性化 (linerization),变成一种更类似目标代码的中间表示;我们将其称为 中间代码 (intermediate code)。
下面这张图也可以充分地体现出 IR 在减省工作量上的重要意义:
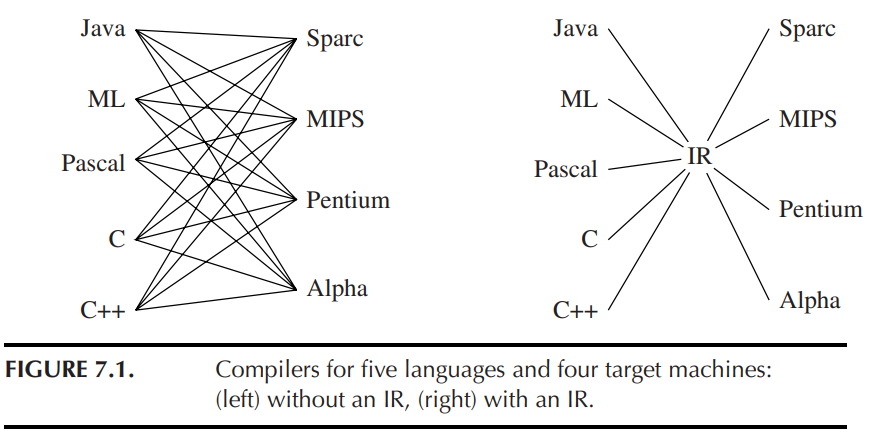
中间代码有很多种类,本节介绍 三地址码 three-address code 和 P-代码 P-code;值得说明的是即使这两种确定的中间代码也有很多不同的具体形式。我们主要讨论一些普遍特性。
6.1.1 三地址码¶
三地址码用来表示算术表达式求值,形如 x = y op z;例如下图 AST 对应的三地址码就是:
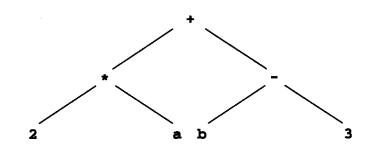
t1 = 2 * a
t2 = b - 3
t3 = t1 + t2
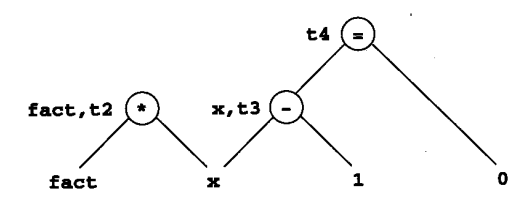
当然,代码不全由算术运算组成,因此三地址码也有一些其他形式的扩展内容。例如下图左边的程序代码对应的三地址码如下图右边所示:

当然,如果生成中间代码只是编译中的一个步骤,我们可以不必将其打印成文本,再从文本中读取然后翻译成目标代码。相反,我们可以直接在程序中用一定的数据结构记录这些中间代码。
对于三地址码,保存其信息需要 3 个地址以及 1 个操作符。因此我们用 四元式 quadruple 的方式来存储三地址码。例如上面的三地址码用四元式表示就是:

_表示不需要使用的地址,置为空。
三地址码另一个不同的实现是用自己的指令来代表临时变量,这样地址域从 3 个减少到了 2 个,目标地址总是一个临时变量,用行号表示。这种实现方式称为 三元式 triple。前述三地址码用三元式表示就是:
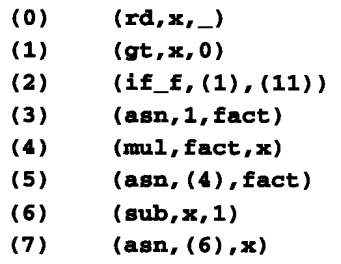
这里形如(1)的其实就是访问行号为 1 的语句运行后的结果。
我们具体来探讨一些代码生成技术。
对于一些基本的操作和计算,我们可以通过属性文法的方式来生成对应的中间代码:

为了执行一些 地址计算和指针引用,可以引入类似 C 语言的取值和取址操作符&和*:
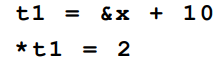
为了方便 数组访问,可以引入[] =和= []形式的三地址码,例如:
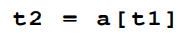
当然,也可以利用上面的地址计算方式写成:

其中,elem_size()是查阅符号表可以直接得到的内容,在实际生成中间代码时会用字面量替代。
对于 结构体访问,例如 x.j = x.i,可以翻译成如下三地址码:

同样的,field_offset()也是生成中间代码时查阅符号表就可以得知并替代的值。
对于控制语句,我们的生成稍微复杂,但是也差不多。例如if (E) S1 else S2可以翻译为:
t1 = <code to evaluate E>
if_false t1 goto L1
<code for S1>
goto L2
label L1
<code for S2>
label L2
while(E) S可以翻译为:
label L1
t1 = <code to evaluate E>
if_false t1 goto L2
<code for S>
goto L1
label L2
对于函数调用,三地址码也是比较清晰的:

为什么需要begin_args?不知道,在问了。(老师不理我)
6.1.2 P-Code¶
P-Code 的运行依赖一个临时的栈。例如,2 * a + (b - 3)的 P-Code 如下:

可以看到,mpi, sbi, adi这些操作都是从栈上弹出 2 个操作数,进行计算,再压回栈上的。
对于赋值语句x := y + 1,其 P-Code 是:


即,在运行sto之前,栈顶两个元素是y + 1的值以及x的地址;sto将它们弹出并将值写入地址。
之前我们讨论的代码:

它对应的 P-Code 如下:

可以注意到,这种代码比三地址码更接近实际的汇编代码。
为了方便 地址计算,P-Code 有这两条指令:
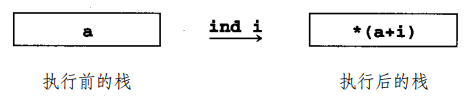
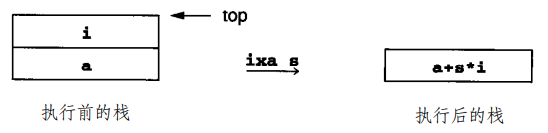
这样我们就可以做数组引用和赋值了:

结构体也类似:

对于 控制语句:
if(E) S1 else S2
<code to evaluate E>
fjp L1
<code for S1>
ujp L2
lab L1
<code for S2>
lab L2
while(E) S
lab L1
<code to evaluate E>
fjp L2
<code for S>
ujp L1
lab L2
函数调用:

mst就类似于begin_args,从这种指令生成的目标代码将为一个新调用在栈上建立一个活动记录。
P-代码在许多方面比三地址码更接近于实际的机器码。 P-代码指令也需要较少地址;我们已见过的都是一地址或零地址指令,另一方面, P-代码在指令数量方面不如三地址码紧凑, P-代码不是自包含的,指令操作隐含地依赖于栈 (隐含的栈定位实际上就是“缺省的”地址),栈的好处是在代码的每一处都包含了所需的所有临时值,编译器不用如三地址码中那样为它们再分配名字。
6.2 代码优化简述¶
6.2.1 代码优化的主要来源¶
- Register allocation,寄存器比较少,但是变量和临时变量都要用
- Unnecessary operations,局部到整体都有
- Common subexpr elimination,公共子表达式消除,记录重复表达式的计算结果
- Unreachable / dead code,消除不可达代码可以减小目标代码,同时可以减少一些不必要的判断和跳转
- Jump optimization,跳到下一条语句,或者跳到跳转语句的都可以优化
- Costly operations,通过比源代码更小的代价实现操作
- Reduction in strength,强度消减,
x * 3=>x + x + x - Constant folding,常量折叠,若有
const int a = 4;则a + 2=>6 - Constant propagation,常量传播,关注变量在局部或全局为恒定值的情况,从而更好实现折叠等
- Procedure inlining,过程内嵌,将过程体原地展开,从而减少调用的开销
- Tail recursion removal,尾递归:如果一个函数的返回值要么是一个变量,要么是调用它本身的返回值,那么这是一种尾递归的情形;其特殊性在于,这种情况下当前 activation record 中的传入参数已经不重要了,可以直接覆盖掉;也即不需要更多的栈空间,更进一步地可以很容易地直接改为循环。
- Predicting Program Behavior,可以通过静态分析预测,也可以通过插桩统计程序运行的信息,例如更有可能运行的分支、过程等。
6.2.2 优化分类¶
按优化的时机分类,有:
- Peephole optimization,窥孔优化。生成目标代码后在目标代码上进行优化;由于通常只能在局部优化所以得名。
- Target-level optimization,目标代码级优化。在生成目标代码前,结合目标机器的特性进行优化。
- Source-level optimization,源代码级优化。在生成目标代码前,以机器无关的方式进行优化。
按优化的范围分类,有:
- local,限于线性部分 (straight-line segment of code) 的优化,即没有跳进跳出的语句的语句块。一个最大的线性部分称为 基本块 (basic block)。
- global,单个过程内。
- interprocedural,过程间。
6.2.3 优化的数据结构和实现技术¶
当考虑 global 或者 interprocedural 的优化时,问题变得复杂了起来;一种分析方式叫做 数据流分析 (dataflow analysis),实现的主要数据结构是 流图 (flow graph)。流图的结点是 basic block,边是跳转语句。例如,左下图代码的流图如右图所示:

流图以及每个基本块都可以从中间代码一次遍历中构造完成。每个新的基本块识别如下:
- 第 1 条指令开始一个新基本块
- 每个转移目的标签开始一个新基本块
- 每条跟随在转移之后的指令开始一个新基本块
有了流图之后,我们可以对基本块建立 DAG(有向无环图)用来跟踪代码中的计算和赋值。上图基本块 B3 的 DAG 如下图所示:
可以看到,拷贝操作不创建新结点,只是给结点增加一个标号。
因为有多种拓扑顺序,可以从 DAG 中产生许多不同代码序列;可以结合目标机器的能力选出比较好的。例如,上图的 DAG 就可以生成一个更简短的三地址指令:
颜色主题调整
评论区~
有用的话请给我个赞和 star =>
快来跟我聊天~