Abstract
Relational Model 是一种基于 关系 的 Data Model。它的关键思想包括:
- 将数据组织在简单的关系结构中,程序只需要和关系交互
- 实际的物理存储方式(如何将数据存储在物理设备中)交给 DBMS 的具体实现,程序不感知
- 使用 high level 的语言访问数据(描述要做什么而非怎么做),DBMS 寻找最有效的做法
值得提及的是,虽然在今天看来,将应用程序和物理存储隔离是理所当然的,但在当时却是开创性的。
Relational Model
Warning
在本文讨论中,可以先不考虑具体的声明语法和实现逻辑,从概念层面理解即可。
Relation 表示的是一组对象(attribute)之间的某种联系,用 N 元组 (n-tuple) 的无序集合表示。
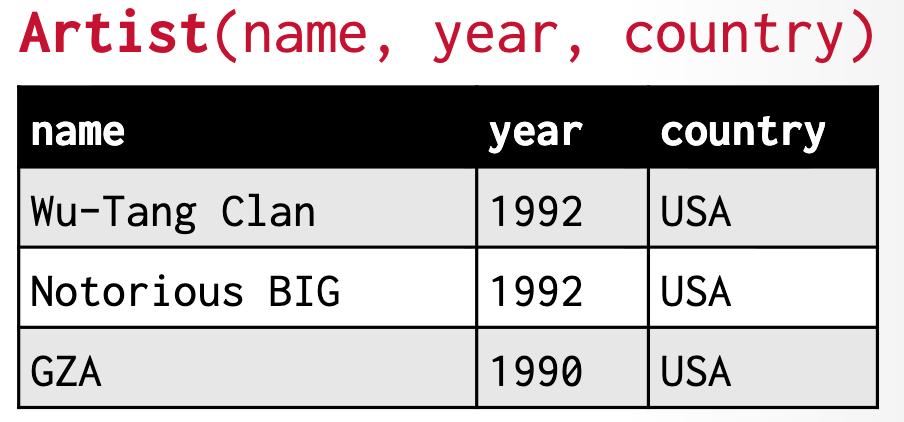
Relation 可以用 tables 表示,我们用 n 列的 table 来表示 n 元组,每一列对应一个属性。如下的 table 表示的是 Artists,它有 3 个属性:name, year, country。
每一行是一个 record,也就是一个 n-tuple,表示 relation 中的一个元素,在下面的例子中也就是一个 artist 的信息。
Domain
Abstract
一个 attribute 的 domain 是这个 attribute 的合法取值的集合。
对于一个 relation 的每一个 attribute,都有一个合法取值的集合,称为这个 attribute 的 domain。
如果一个 domain 中的所有元素(即所有的合法取值)都被视为不可分割的单元,那么我们称这个 domain 是 atomic 的。这里「视为」的含义是:我们在 使用 这些值时不再对它们进行拆分,这与这些值本身无关。例如,宿舍地址「碧峰 1 舍 617」既可以作为一个不可分割的单元进行使用(例如收信地址),也可以被分割为若干单元(例如宿舍楼「碧峰 1 舍」,寝室号「617」)进行使用。那么如果我们如前面那样使用,那么这个 domain 是 atomic 的;如果如后面那样使用,则它是 nonatomic 的。
若无特殊说明,我们默认所有 attribute 都具有 atomic domain。
另外,有些 attribute 可能允许 NULL 值,通常表示未知或不存在,这也是 domain 上的一个扩展。
Schema
Abstract
relation 的 schema 用于描述 relation 的结构和约束。
例如
artist(name, year, country)是一个 relation schema,它描述了 artist relation 的结构和约束。
我们用 relation schema 来描述一个 relation。需要描述的内容包括这个 relation 包含哪些 attribute,以及每个 attribute 对应的 domain,还有这个 relation 的一些约束条件(integrity-constraint)。
Constraints
Abstract
约束条件规定一个 relation 中一个 tuple,或多个 tuple 之间,又或者多个 relation 中的 tuple 之间的值应该满足的条件。
约束条件是丰富的,例如:
- 年龄应该是一个自然数
- unique constraint: 身份证号在 relation (table) 中应该是唯一的
- referential (foreign key) constraint: 艺术家国籍应该在国家列表中
- 备注应该不为 NULL (这不一定永远成立,但当然可以是一个 table 的要求)
Keys
Superkey 的引入和定义
由于 relation 是 tuple 的一个集合,我们必须采取方式保证其中的 tuple 彼此不同;即,不允许两个 tuple 的所有 attribute 的值完全相同。
当然,保证所有 tuple 是 unique 的,并不需要检查其所有 attribute 的值。例如,在人员名单 table 中,身份证号就可以唯一标识一个 tuple;在宿舍成员 table 中,宿舍号 + 床号也可以唯一标识一个成员。
我们称 Superkey 是 relation 中一个或多个属性的集合,其值可以唯一标识一个 tuple。也就是说,不存在两个 tuple 在 superkey 的所有属性上的取值都相同。
由于任何 superkey 的超集都是 superkey,因此 superkey 可能包含冗余或无关的属性。
对于 relation ,设 是 的所有属性的集合, 是 的 superkey,当且仅当对于 的任何实例中的任意两个不同的 tuple ,它们在 上的取值也不相同,即 。
Candidate keys 和 Primary key
由于任何 superkey 的超集都是 superkey,因此 superkey 可能包含冗余或无关的属性。我们希望找到最简单的属性组合。
Candidate key 是 superkey,且它的任何真子集都不是 superkey。也就是说,candidate key 是极小的 superkey。
一个 relation 可能有多个 candidate key。例如,在浙江大学的学生名单中,身份证号、学号、宿舍号 + 床号都可能是 candidate key。
Primary key 是数据库设计者从 candidate key 中选择的用于唯一标识该数据库中 tuple 的 candidate key。
选择 primary key 需要仔细考虑。例如,在浙江大学的学生名单中,姓名不适合作为 primary key,因为可能存在重名;宿舍号 + 床号也不适合,因为这些值可能会发生变化。建议选择稳定、不易变化或变化很少的属性作为 primary key。
在一些场景中,例如 Artist(name, year, country) 的例子里,即使 {name, year, country} 也不是一个 superkey,因为可能有两个艺术家这些信息都相同。这种情况下,我们可以引入一个自增 ID 作为 primary key,即 Artist(id, name, year, country),其中 id 是自增的:
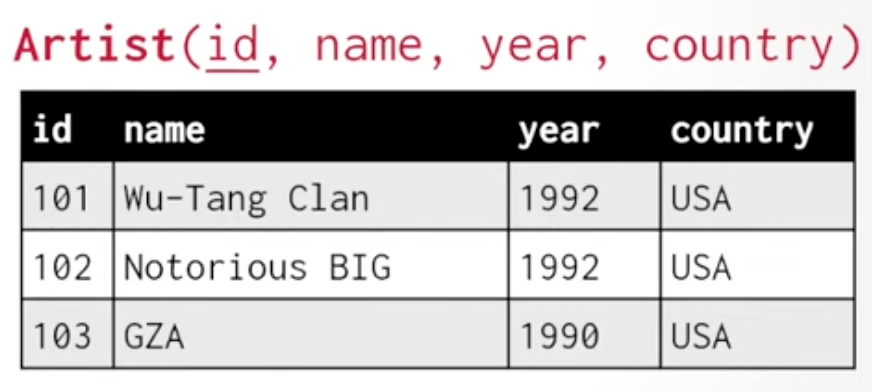
图中下划线标识出了 primary key。
在一些数据库 (如 MySQL) 中,如果一个 relation 没有显式定义 primary key,那么会自动添加一个自增 id 用作 primary key。在另一些数据库 (如 SQLite) 中,即使定义了 primary key,也会添加一个自增 id 用作 primary key,而定义的 primary key 则视为 unique constraint。
Foreign key constraint (Referential constraint)
如果 relation 中的某个属性包含 relation 的 primary key,则称该属性为 的 foreign key。
此时, 称为 referencing relation, 称为 referenced relation。
和 之间的这种关系称为 foreign key constraint。
例如,我们通过一张单独的表 ArtistAlbum 维护 Album 和 Artist 之间的关系,其中使用了外键约束:
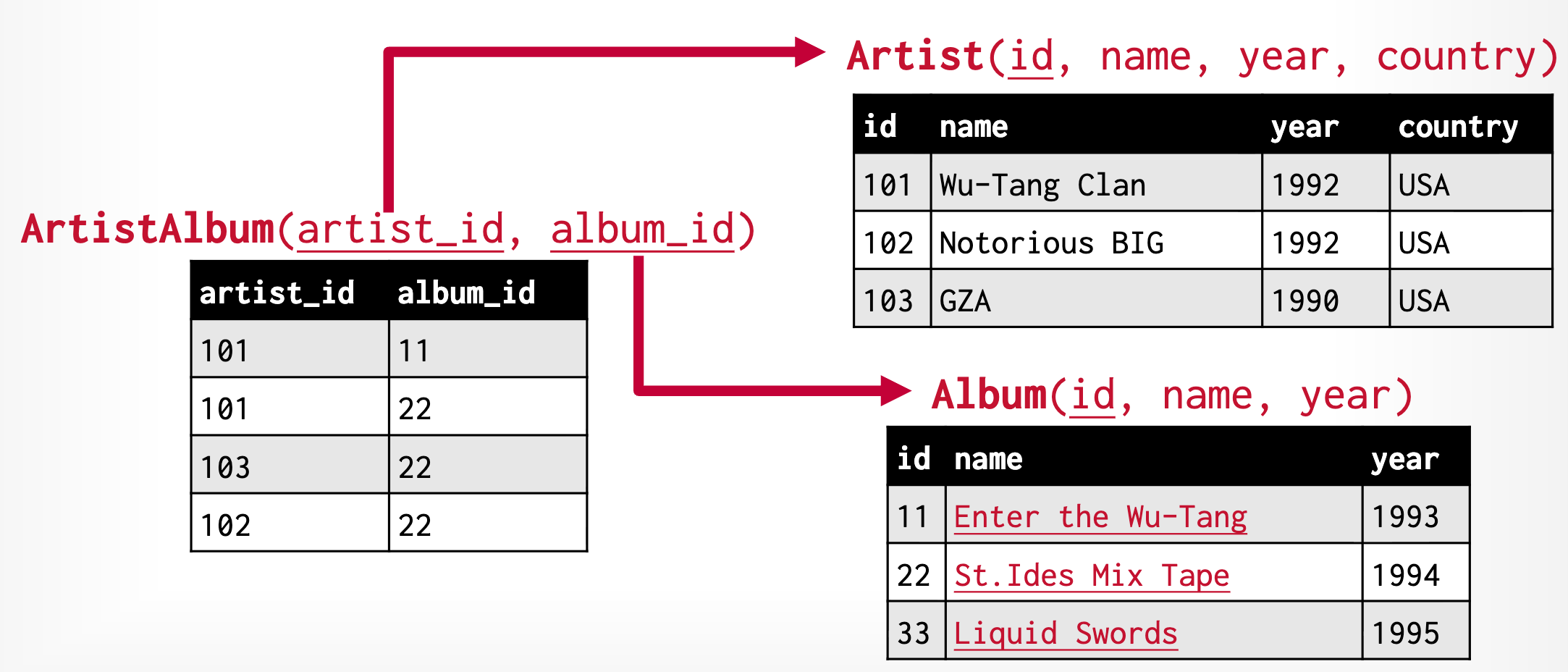
不直接在 Album 表中维护 Artist 的信息,是因为一个 Album 可能由多个 Artist 参与。
外键约束除了可以保证引用关系的正确性外,还可以实现级联 (Cascade) 删除和更新,例如当删除一个 Artist 时,可以指定删除其所有 Album;或者如果一个 Artist 有 Album,则不能删除这个 Artist。